
À la VAP, nous travaillons depuis longtemps d’arrache-pied sur le sujet des écosystèmes de données. En 2022, nous avons suggéré au Bureau de coordination pour la mobilité durable (COMO) de mettre au point une plateforme de données, et nous faisons progresser le développement de l’infrastructure de données sur la mobilité (MODI). Dans cet article de notre blog, nous nous proposons de poursuivre le dialogue et de montrer pourquoi les écosystèmes de données devraient faire partie de la vision de tous les acteurs du fret ferroviaire.
Les enjeux:
- La complexité, un défi de taille
- À petits pas vers la grande vision
- Exploiter à fond l’inépuisable potentiel de données
- Pour une poursuite de notre dialogue
La complexité, un défi de taille
Les écosystèmes de données sont hautement complexes et couvrent plusieurs champs thématiques (cf. illustration 1). Pour rendre ces écosystèmes de données utilisables et rentables, nous devons prendre en compte l’ensemble des souhaits et besoins des acteurs ainsi que les éventuelles restrictions.
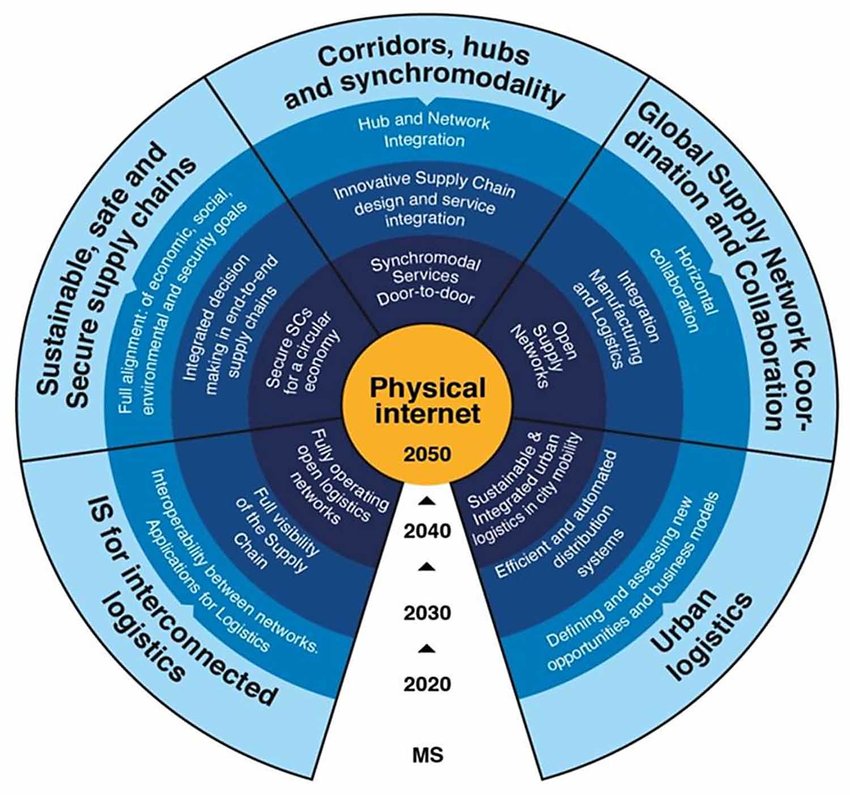
Illustration 1: la vision de l’interconnectivité numérique et opérationnelle comprend des domaines thématiques extrêmement exigeants.
À l’occasion de notre Forum Fret ferroviaire 2023, le Dr Matthias Prandtstetter, Senior Scientist et Thematic Coordinator à l’AIT, Austrian Institute of Technology AIT, ainsi que Monika Zosso Lundsgaard-Hansen, co-cheffe de la section Affaires directoriales à l’OFT, ont donné des aperçus de l’état actuel d’avancement des initiatives et réflexions. Les deux expert·e·s sont unanimes: les progrès à accomplir dans le secteur ferroviaire seront une tâche de longue haleine et ardue.
À petits pas vers la grande vision
La vision d’un écosystème de données intelligent et peut-être capable de prendre ses décisions de manière autonome pourrait par exemple être réalisée selon les phases suivantes (description non exhaustive):
1. Mise à disposition des données de base (p. ex. avec MODI)
- Qualité garantie
- Caractère unique de tout bloc de données (c’est-à-dire définitions univoques)
- Accessibilité / transparence pour toutes les parties prenantes
- Possibilité de développer des applications mobiles sur le marché et d’élargir les fonctionnalités
2. Activation de la plaque tournante d’échange de données (p. ex. DX Intermodal de Hupac)
- Échanges entre 2 ou plusieurs entreprises actives sur la plaque tournante
- Blocs de données supplémentaires (avec ou sans restrictions pour des acteurs ou entreprises donnés)
- Possibilités de réservation de relations partielles ou complètes
3. Création d’un écosystème de données
- Donner accès aux données historiques pour les premières possibilités d’analyse
- Banques de données (raccorder les données de base et/ou les blocs de données disponibles avec des restrictions)
4. Utilisation de la technologie du blockchain
- Les données et blocs de données sont connectés de manière optimale.
- Transparence absolue des coûts et des prix
- Augmentation de la sécurité dans les échanges de données
- Développement et exécution plus efficaces de l’ensemble
5. Mise en œuvre de la vision d’un internet physique
- Système mondial ouvert basé sur une connectivité internet physique, numérique et opérationnelle
- Applique les protocoles, les interfaces et la modularisation.
- Certaines décisions sont prises par l’écosystème – et non par des acteurs donnés.
Actuellement, le secteur ferroviaire se trouve en phase 1 et 2, quoique seulement ponctuellement. La loi fédérale concernant l’infrastructure de données sur la mobilité (MODIG) de l’OFT aborde tous les champs thématiques pertinents. DX Intermodal est déjà opérationnel dans le trafic combiné (TC) et reprend certains points de la phase 2. Il ne sera possible d’obtenir des avantages globaux pour la logistique de fret ferroviaire que si l’on prend en compte toutes les formes de production du transport de marchandises et l’ensemble de la chaîne de transport («porte-à-porte»). Pour ce faire, il faudra intégrer des éléments de l’intelligence artificielle.
Exploiter à fond l’inépuisable potentiel de données
Parti d’un simple engouement, le big data est devenu une véritable mégatendance; les données collectées recèlent un potentiel quasiment infini et permettent de créer des modèles commerciaux numériques innovants et disruptifs et d’améliorer les prévisions pour prendre les bonnes décisions commerciales. Toutefois, cela ne vaut que pour les données disponibles dans la qualité et la granularité appropriées. De plus, les acteurs doivent être en mesure d’extraire des données les bonnes informations et donc les connaissances souhaitées, puis de les interpréter et les utiliser correctement. Cela pose un certain nombre de défis aux partenaires de l’écosystème:
Avantages pour le système vs avantages individuels
Certaines entreprises disposent déjà de systèmes de données internes. Elles collectent les données des appareils montés sur les locomotives et les wagons et les utilisent pour procéder à des optimisations ou les transmettent à des tiers. Les entreprises acquièrent ainsi des avantages concurrentiels et des sources de revenus supplémentaires. Pourquoi ces entreprises devraient-elles donc participer à des écosystèmes de données? Parce que l’optimisation de son propre système ne bénéficie pas nécessairement au système dans son ensemble ou au client final. Si par exemple divers acteurs individuels vendent les mêmes données à des tiers contre rémunération, le système renchérit, car pour chaque transfert de données, de l’argent circule. De plus, les différents acteurs peuvent combiner leurs blocs de données dans le cadre d’un écosystème de données et ainsi contribuer à l’efficience de l’ensemble du système, par exemple les horaires de départ ou d’arrivée prévus. Dans ce contexte, il est indispensable de clarifier les questions de la souveraineté sur les données.
Obligation vs volontariat
L’État est et reste le plus grand bailleur de fonds du système ferroviaire. Il devrait être désireux de soulager ses propres finances et donc les contribuables. La mise à disposition de données d’utilité publique est de nature à améliorer l’efficience. À cet égard aussi, certaines questions attendent une réponse: les partenaires de l’écosystème doivent-ils être obligés de fournir des blocs de données? Au sein d’un écosystème de données, doit-il être possible de compenser des investissements individuels antérieurs ou de les mettre en balance avec les subventions reçues? Ou bien la participation à un écosystème de données doit-elle rester volontaire, avec le risque que trop peu de participants alimentent la plateforme en données?
Données vs données
Tous les éléments de données n’ont pas la même valeur pour un écosystème de données. Ainsi, il faut définir clairement dès le départ avec quel objectif et pour servir quelle utilité générale un acteur déposera ses éléments de données sur une plateforme de données. En outre, afin d’éviter les discussions à caractère affectif, il convient de distinguer les données opérationnelles, techniques et commerciales. Enfin, un critère décisif pour la crédibilité et la durabilité d’un écosystème de données est la qualité garantie par le propriétaire des données ou par un service chargé de la qualité nouvellement créé.
Pour une poursuite de notre dialogue
À la VAP, nous souhaitons faire bénéficier l’ensemble du secteur ferroviaire du potentiel des écosystèmes de données et ainsi améliorer la compétitivité de la branche. C’est pourquoi nous nous engageons dans ce contexte en faveur de plusieurs initiatives, projets de recherche et produits établis, à savoir:
- Développement de l’infrastructure de données sur la mobilité MODI, en coopération avec l’OFT.
- Espace européen commun des données relatives à la mobilité (EMDS), une initiative de l’UE.
- Arbeitskreis der Logistik (AKL) (Cercle de travail de la logistique), dont nous avons repris la direction.
Si vous aussi, vous souhaitez contribuer à forger l’avenir du secteur ferroviaire, Jürgen Maier se fera un plaisir de vous écouter.


